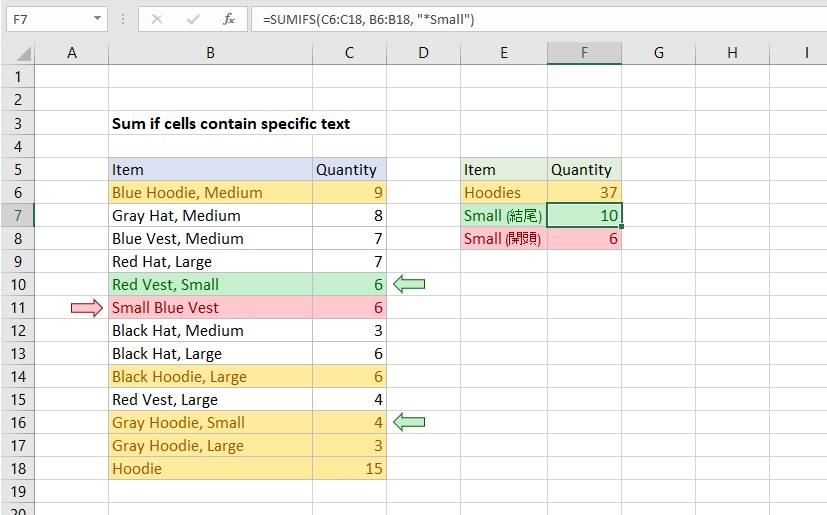
為 UHD BD 進行備份需準備以下三件事情:1. 準備一台可支援的光碟機:像是 LG BU40N、Archgon UHD 藍光燒錄機 (MD-8107-U3YC-UHDB-S)、Buffalo BRUHD-PU3-BK,或其他官方列出可支援的機器型號2. 使用 DVDFab UHD Drive Tool 重刷機器韌體,降至可支援版本3. 使用 DVDFab 進行備份 UHD BD 與一般藍光光碟的不同 UHD BD 的外型雖然與一般藍光光碟長的一樣,但實際 UHD BD 的光碟片以一般藍光光碟為基礎進行改良,調整內部數據的紀錄方式及物理特性。改良後的 UHD BD 可以容納更多的資料,最高可以容納三層的儲存空間,每層可寫入 33GB 的資料量,等於最高可寫入將近 100GB 的容量。因此需要可以相容的光碟機才能讀取 UHD BD 的內容。這還只是光碟讀取層面的相容性需求。 若想要在電腦上播放 4K UHD BD 的電影,除了需要相容的光碟機之外,還需要有相容的軟硬體才能播放。其原因是因為 UHD 藍光光碟所使用的數位版權管理(Digital Rights Management,DRM)機制需要搭配 Intel 處理器的 SGX (Intel® Software Guard...